This post was originally published on the O'Reilly Radar.
There is a huge debate right now about making academic literature freely accessible and moving toward open access. But what would be possible if people stopped talking about it and just dug in and got on with it?
NASA's Astrophysics Data System (ADS), hosted by the Smithsonian Astrophysical Observatory (SAO), has quietly been working away since the mid-'90s. Without much, if any, fanfare amongst the other disciplines, it has moved astronomers into a world where access to the literature is just a given. It's something they don't have to think about all that much.
The ADS service provides access to abstracts for virtually all of the astronomical literature. But it also provides access to the full text of more than half a million papers, going right back to the start of peer-reviewed journals in the 1800s. The service has links to online data archives, along with reference and citation information for each of the papers, and it's all searchable and downloadable.
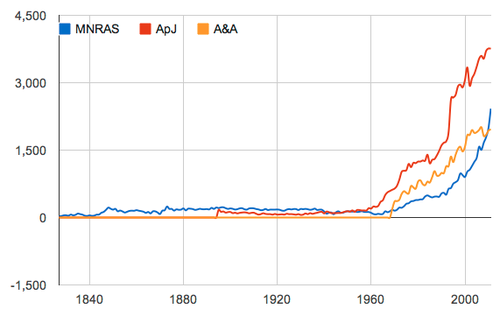 Number of papers published in the three main astronomy journals each year. CREDIT: Robert Simpson
Number of papers published in the three main astronomy journals each year. CREDIT: Robert SimpsonIt also makes astronomy almost uniquely well placed for interesting data mining experiments, experiments that hint at what the rest of academia could do if they followed astronomy's lead. The fact that the discipline's literature has been scanned, archived, indexed and catalogued, and placed behind a RESTful API makes it a treasure trove, both for hypothesis generation and sociological research.
For example, the .Astronomy series of conferences is a small workshop that brings together the best and the brightest of the technical community: researchers, developers, educators and communicators. Billed as "20% time for astronomers," it gives these people space to think about how the new technologies affect both how research and communicating research to their peers and to the public is done.
It should perhaps come as little surprise that one of the more interesting projects to come out of a hack day held as part of this year's .Astronomy meeting in Heidelberg was work by Robert Simpson, Karen Masters and Sarah Kendrew that focused on data mining the astronomical literature.
The team grabbed and processed the titles and abstracts of all the papers from the Astrophysical Journal (ApJ), Astronomy & Astrophysics (A&A), and the Monthly Notices of the Royal Astronomical Society (MNRAS) since each of those journals started publication — and that's 1827 in the case of MNRAS.
By the end of the day, they'd found some interesting results showing how various terms have trended over time. The results were similar to what's found in Google Books' Ngram Viewer.
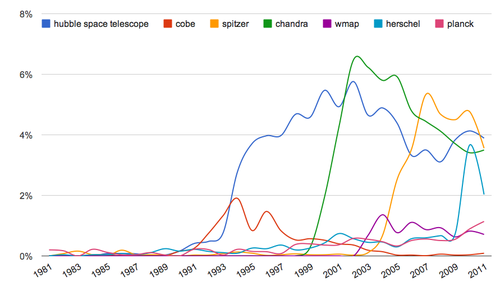 The relative popularity of the names of telescopes in the literature. Hubble, Chandra and Spitzer seem to have taken turns in hogging the limelight, much as COBE, WMAP and Planck have each contributed to our knowledge of the cosmic microwave background in successive decades. References to Planck are still on the rise. CREDIT: Robert Simpson.
The relative popularity of the names of telescopes in the literature. Hubble, Chandra and Spitzer seem to have taken turns in hogging the limelight, much as COBE, WMAP and Planck have each contributed to our knowledge of the cosmic microwave background in successive decades. References to Planck are still on the rise. CREDIT: Robert Simpson.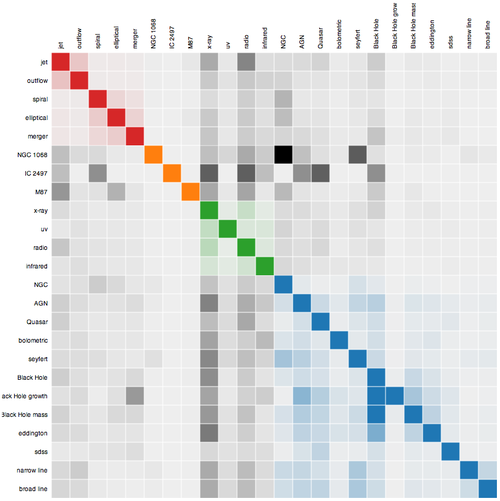 Correlation between terms related to Active Galactic Nuclei (AGN). The opacity of each square represents the strength of the correlation between the terms. CREDIT: Robert Simpson.
Correlation between terms related to Active Galactic Nuclei (AGN). The opacity of each square represents the strength of the correlation between the terms. CREDIT: Robert Simpson.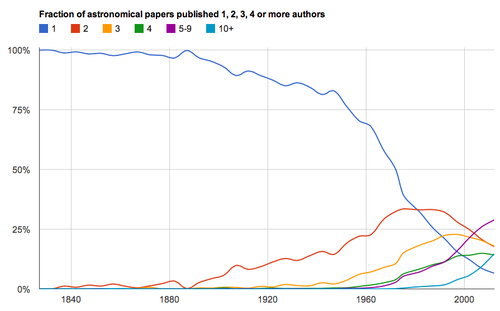 Fraction of astronomical papers published with one, two, three, four or more authors. CREDIT: Robert Simpson
Fraction of astronomical papers published with one, two, three, four or more authors. CREDIT: Robert Simpson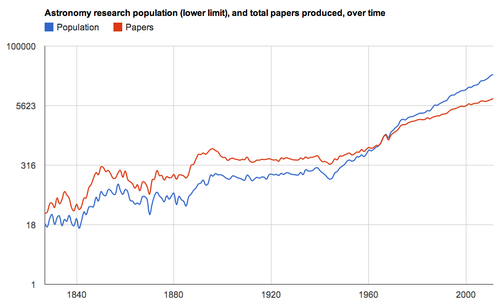 Compare the number of "active" research astronomers to the number of papers published each year (across all the major journals). CREDIT: Robert Simpson.
Compare the number of "active" research astronomers to the number of papers published each year (across all the major journals). CREDIT: Robert Simpson.Behind the project and what lies ahead
I recently talked with Rob about the work he, Karen Masters, and Sarah Kendrew did at the meeting, and the work he's been doing since with the newly gathered data.
What made you think about data mining the ADS?
Robert Simpson: At the .Astronomy 4 Hack Day in July, Sarah Kendrew had the idea to try to do an astronomy version of BrainSCANr, a project that generates new hypotheses in the neuroscience literature. I've had a go at mining ADS and arXiv before, so it seemed like a great excuse to dive back in.
Do you think there might be actual science that could be done here?
Robert Simpson: Yes, in the form of finding questions that were unexpected. With such large volumes of peer-reviewed papers being produced daily in astronomy, there is a lot being said. Most researchers can only try to keep up with it all — my daily RSS feed from arXiv is next to useless, it's so bloated. In amongst all that text, there must be connections and relationships that are being missed by the community at large, hidden in the chatter. Maybe we can develop simple techniques to highlight potential missed links, i.e. generate new hypotheses from the mass of words and data.
Are the results coming out of the work useful for auditing academics?
Robert Simpson: Well, perhaps, but that would be tricky territory in my opinion. I've only just begun to explore the data around authorship in astronomy. One thing that is clear is that we can see a big trend toward collaborative work. In 2012, only 6% of papers were single-author efforts, compared with 70+% in the 1950s.
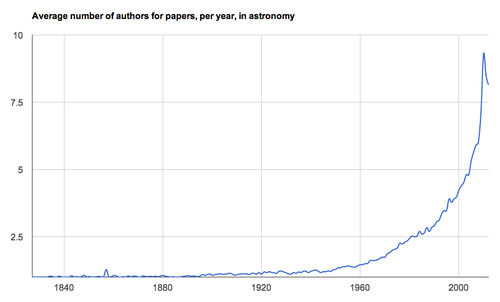 The above plot shows the average number of authors, per paper since 1827. CREDIT: Robert Simpson.
The above plot shows the average number of authors, per paper since 1827. CREDIT: Robert Simpson.What about citations? Can you draw any comparisons with h-index data?
Robert Simpson: I haven't looked at h-index stuff specifically, at least not yet, but citations are fun. I looked at the trends surrounding the term "dark matter" and saw something interesting. Mentions of dark matter rise steadily after it first appears in the late '70s.
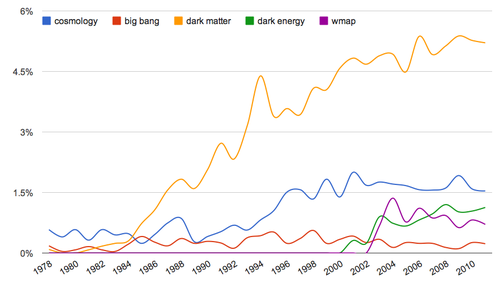 Compare the term "dark matter" with a few other related terms: "cosmology," "big bang," "dark energy," and "wmap." You can see cosmology has been getting more popular since the 1990s, and dark energy is a recent addition. CREDIT: Robert Simpson.
Compare the term "dark matter" with a few other related terms: "cosmology," "big bang," "dark energy," and "wmap." You can see cosmology has been getting more popular since the 1990s, and dark energy is a recent addition. CREDIT: Robert Simpson.Can you see where work is dropped by parts of the community and picked up again?
Robert Simpson: Not yet, but I see what you mean. I need to build a better picture of the community and its components.
Can you build a social graph of astronomers out of this data? What about (academic) family trees?
Robert Simpson: Identifying unique authors is my next step, followed by creating fingerprints of individuals at a given point in time. When do people create their first-author papers, when do they have the most impact in their careers, stuff like that.
What tools did you use? In hindsight, would you do it differently?
Robert Simpson: I'm using Ruby and Perl to grab the data, MySQL to store and query it, JavaScript to display it (Google Charts and D3.js). I may still move the database part to MongoDB because it was designed to store documents. Similarly, I may switch from ADS to arXiv as the data source. Using arXiv would allow me to grab the full text in many cases, even if it does introduce a peer-review issue.
What's next?
Robert Simpson: My aim is still to attempt real hypothesis generation. I've begun the process by investigating correlations between terms in the literature, but I think the power will be in being able to compare all terms with all terms and looking for the unexpected. Terms may correlate indirectly (via a third term, for example), so the entire corpus needs to be processed and optimised to make it work comprehensively.
Science between the cracks
I'm really looking forward to seeing more results coming out of Robert's work. This sort of analysis hasn't really been possible before. It's showing a lot of promise both from a sociological angle, with the ability to do research into how science is done and how that has changed, but also ultimately as a hypothesis engine — something that can generate new science in and of itself. This is just a hack day experiment. Imagine what could be done if the literature were more open and this sort of analysis could be done across fields?
Right now, a lot of the most interesting science is being done in the cracks between disciplines, but the hardest part of that sort of work is often trying to understand the literature of the discipline that isn't your own. Robert's project offers a lot of hope that this may soon become easier.
Maybe NASA should go hire a third-party archiving solutions provider to streamline these kinds of data handling.
ReplyDeleteGreat Article
ReplyDeleteData Mining Project Titles with Abstract
Project Centers in Chennai
JavaScript Training in Chennai
JavaScript Training in Chennai
fauquier traffic lawyer
ReplyDeleteMining the astronomical literature involves collecting, processing, and analyzing data from various sources, such as scientific journals and conferences. Techniques include keyword extraction, topic modeling, named entity recognition, sentiment analysis, data visualization, knowledge discovery, validation and interpretation, and application. This process helps researchers unlock valuable knowledge, accelerate scientific discovery, and advance our understanding of the cosmos. It can be applied to various areas within astronomy and astrophysics.
This is fascinating! The availability of astronomical literature through NASA's ADS is truly groundbreaking. It reminds me of the freedom and excitement you feel when speeding down a snowy hill in Snow Rider 3D. Imagine if all academic fields had such easily accessible data. The possibilities for research and discovery would be endless, accelerating progress just like a perfect downhill run. Data mining here could reveal patterns we've never imagined.
ReplyDeleteRobert’s approach to mining scientific literature is fascinating! The idea of uncovering hidden correlations between terms could lead to some groundbreaking discoveries. It reminds me of how Retro Bowl surprises you with unexpected plays—sometimes the best insights come from the least obvious connections. Excited to see where this project goes next!
ReplyDeleteBlueScreenView is a game-changer for Windows troubleshooting. The way it presents detailed crash reports makes understanding errors simple, even for those with limited technical knowledge. It’s a must-have utility for keeping your system stable and healthy.
ReplyDeleteThe versatility of Pyqtgraph is simply amazing! From real-time plotting to complex data visualization, this website provides all the resources needed to utilize the library efficiently. It’s perfect for developers who prioritize speed and customization.
ReplyDeleteThis astronomical ADB is an essential tool for moving forward in your life. Through it, scientists can learn valuable information from scientists. For example, perfect cv maker in UAE companies are providing the best CVs. At the same time, this article presents new information to every new person.
ReplyDeleteProPresenter stands out as a professional presentation tool built for real-world use. The interface is clean, and the performance is reliable. Managing lyrics and media is effortless. This website highlights the strengths of ProPresenter in a very clear way.
ReplyDelete